[혼공분석] #4. 데이터 요약하기
4. 데이터 요약하기
1) 통계로 요약하기
(1) 기술통계 구하기
(2) 평균 구하기
(3) 중앙값 구하기
(4) 최솟값/최댓값 구하기
(5) 분위수 구하기
(6) 분산/표준편차 구하기
(7) 최빈값 구하기
2) 분포로 요약하기
(1) 산점도 그리기
(2) 히스토그램 그리기
(3) 상자 수염 그림 그리기
1) 통계로 요약하기
(1) 기술통계 구하기
- [describe() 메서드]로 기술통계를 출력함
- count는 데이터 개수(누락된 값 제외), mean 평균, std 표준편차 등
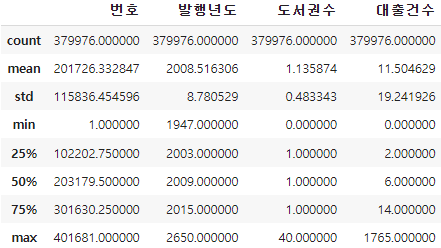
- [include 매개변수]로 데이터 타입 지정 가능함
- object 타입의 열에 대한 통계의 unique는 고유한 값의 개수, top 최빈값, freq 최빈값 개수(빈도 수) 등

(2) 평균 구하기
① for 반복문
- [range() 함수]는 0부터 ()안에 입력된 숫자 직전까지 반복함
- 변수 i에 0,1,2를 대입하여 x[0]+x[1]+x[2]를 sum 값에 누적함
② mean() 메서드
(3) 중앙값 구하기
- 전체 데이터를 순서대로 늘어 놓았을 때, 중앙에 위치한 값 (describe() 메서드의 50% 값)
- 데이터 개수가 짝수인 경우는 중앙의 두 개의 값을 평균함
- [drop_duplicates() 메서드]로 중복된 값을 제거한 후, 중앙값 구하기
(4) 최솟값/최댓값 구하기
① 최솟값
② 최댓값
(5) 분위수 구하기
① 사분위수
- [quantile() 메서드]로 분위수를 지정하여 활용함
- [interpolation 매개변수]로 중앙 값 계산하는 방법을 결정함
- midpoint 두 값 사이의 중앙값, nearest 가까운 값, lower 작은 값, higher 큰 값 등
② 백분위 구하기
- 특정 값이 위치한 백분위는 불리언 배열을 사용하여 비율 계산함
- 10이 위치한 백분위는 10보다 작은지 비교하여 불리언 배열을 만들면, True=1이므로 mean() 메서드를 사용하여 비율을 산출할 수 있음
(6) 분산/표준편차 구하기
① 분산
- 분산은 평균으로부터 데이터가 얼마나 퍼져있는지 나타내는 통계량 (분산이 크면 데이터가 넓게 퍼져있다는 의미)
- 분산은 데이터의 각 값에서 평균을 뺀 다음 제곱한 후, 데이터 개수로 나눔
② 표준편차
- 표준편차는 분산에 제곱근한 것
- 평균(11)보다 표준편차(19)가 크다는 것은 평균보다 훨씬 큰 값이 있다는 것을 의미함
(7) 최빈값 구하기
- 최빈값은 가장 많이 나온 값을 의미함
- 데이터프레임에서 호출하기
- 도서명의 최빈값은 '승정원일기', 출판사의 최빈값은 '문학동네' → 승정원일기 출판사가 문학동네라는 의미는 아님!

2) 분포로 요약하기
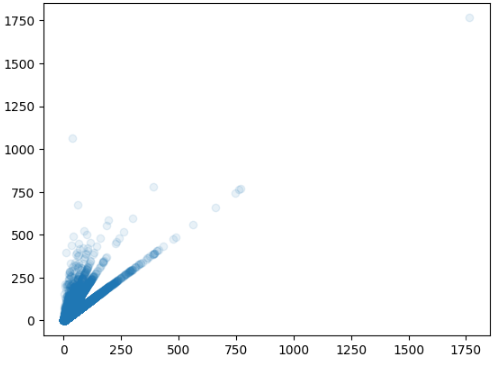
(1) 산점도 그리기, scatter() 함수
- [맷플롯립 패키지]를 이용하여 그래프를 그림
- 산점도는 데이터를 2차원 평면 or 3차원 공간에 점으로 표시하는 그래프임
- [scatter() 함수]에 x축 좌표, y축 좌표를 전달하여 [show() 함수]로 출력함
- [alpha 매개변수]로 투명도 지정할 수 있으며, 데이터가 많이 중첩된 부분은 짙음
(*0에 가까울수록 투명, 1에 가까울수록 불투명)
- '도서권수 당 대출건수'와 '대출건수'는 양의 상관관계를 보임
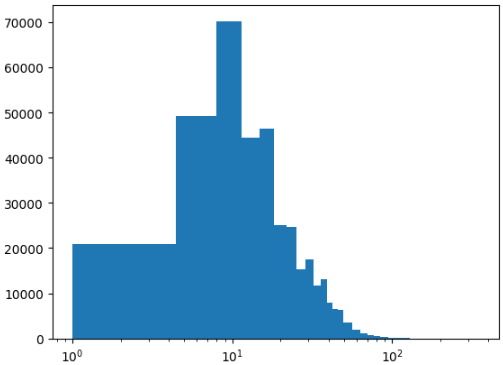
(2) 히스토그램 그리기, hist() 함수
- 히스토그램은 데이터를 일정 구간으로 나누어 구간에 속한 데이터 개수(도수)를 막대로 표현한 그래프
- [hist() 함수]를 이용하며, [bins 매개변수]에 구간 개수를 지정함
- [histogram_bin_edges() 함수]로 구간의 경곗값을 확인
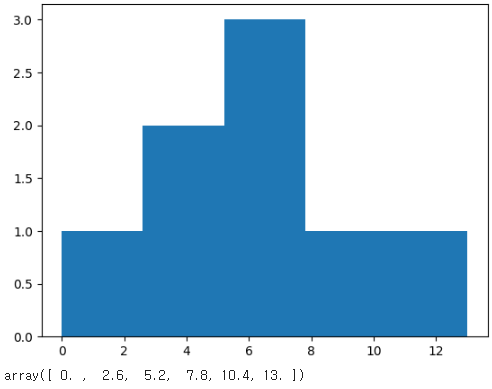
- [randn() 함수]는 실수를 랜덤하게 생성하며, [seed() 함수]는 동일한 난수를 생성해 줌
- 표준정규분포는 평균이 0, 표준편차가 1에 가까움
- 그래프가 한 쪽에 편중되어 그려진다면, xy축에 로그 스케일을 적용하여 구간을 조정함
- [yscale() 함수]는 y축에 로그 함수를 적용해 줌
- 도서명 글자 수는 [apply() 메서드]에 [len() 함수]를 적용하여 만들고, [xscale() 함수]로 x축에 데이터를 골고루 그림
(3) 상자 수염 그림 그리기, boxplot() 함수
![[상자 수염 그림]](https://blog.kakaocdn.net/dn/XqOqZ/btsD5ypYHnX/JHNqhhKW4nvaAIKph7CBYK/img.png)
- 상자 수염 그림은 사분위수, 최솟값, 최댓값으로 여러 특성의 분포를 비교할 수 있는 그래프
- [boxplot() 함수]를 이용하며, 2번 상자 '도서권수'의 사분위수는 모두 1이라서 상자가 보이지 않음
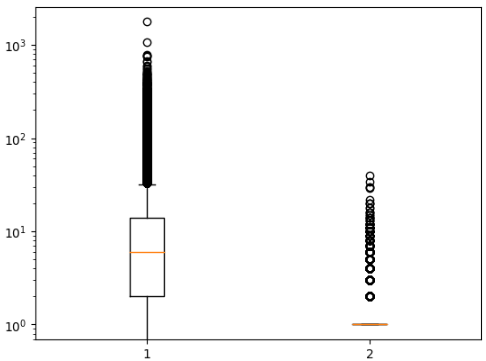
- [vert 매개변수]를 False로 지정하면 수평으로 그릴 수 있음
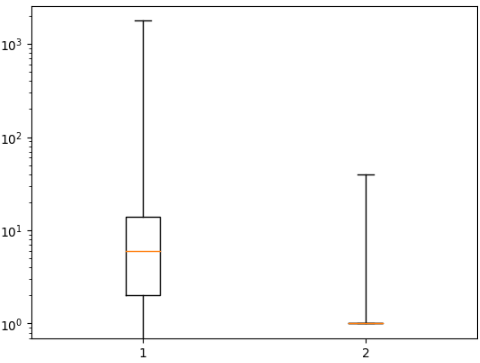
- [whis 매개변수]로 수염 길이를 조정할 수 있음 (기본은 IQR의 1.5배)
- [whis 매개변수]는 백분율 지정도 가능하며, (0, 100)으로 지정하면 0%, 100%에 해당하는 모든 데이터까지 수염을 그림

4주차. 기본 미션
p279. 확인 문제 5번 풀고 인증하기
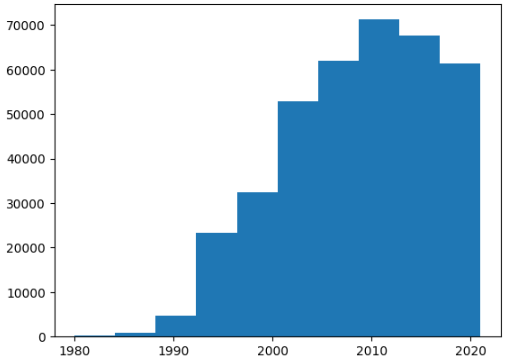
문5. ns_book7 남산도서관 대출 데이터에서 1980년~2022년 사이에 발행된 도서를 선택하여 다음과 같은 '발행년도' 열의 히스토그램을 그려 보세요.
4주차. 선택 미션
Ch.04(04-1)에서 배운 8가지 기술통계량(평균, 중앙값, 최솟값, 최댓값, 분위수, 분산, 표준편차, 최빈값)의 개념을 정리하기
![[기술통계량 예시]](https://blog.kakaocdn.net/dn/kVNTo/btsD0JmpTtX/TcIAchN9ePGPwczSSVyv10/img.png)
| 평균 | 중앙값 | 최솟값 | 최댓값 |
| 데이터값을 모두 더한 후, 데이터 개수로 나눈 값 |
중앙에 위치한 값 | 가장 작은 값 | 가장 큰 값 |
| mean() | median() | min() | max() |
| 분위수 | 분산 | 표준편차 | 최빈값 |
| 일정한 간격으로 나누는 기준점 |
데이터의 분포 정도 | 분산의 제곱근 | 가장 많이 등장하는 값 |
| quantile() | var() | std() | mode() |