[혼공R이] #5. 데이터 가공하기
5. 데이터 가공하기
1) dplyr 패키지
2) 데이터 가공하기
3) 데이터 구조 변형하기
4) 데이터 정제하기
1) dplyr 패키지
(1) dplyr 패키지 설치 및 로드
- dplyr 패키지는 데이터 가공에 유용한 함수가 많은 데이터 처리 필수 패키지임
- install.packages("dplyr") 패키지 설치 필요
- library(dplyr)
(2) 데이터 추출
| 행(관측치) 추출 | 열(변수) 추출 |
| filter(데이터, 조건문) | select(데이터, 변수명1, 변수명2, ...) |
| > filter(mtcars, cyl == 4 & mpg > 20) → cyl 4이면서 mpg 20이상인 데이터만 추출 |
> head(select(mtcars, am, gear)) → am과 gear 데이터만 추출 |
| > mtcars %>% filter(cyl == 4 & mpg > 20) → cyl 4이면서 mpg 20이상인 데이터만 추출 |
> mtcars %>% select(am, gear) → am과 gear 데이터만 추출 > mtcars %>% select(-am) → am만 제외하고 추출 |
(3) 데이터 정렬
| 오름차순 정렬 | 내림차순 정렬 |
| arrange(데이터, 변수명1, 변수명2, ...) | arrange(데이터, 변수명1, ..., desc(변수명)) |
| > head(arrange(mtcars, wt)) → wt 기준으로 오름차순 정렬 |
> head(arrange(mtcars, mpg, desc(wt))) → mpg 기준으로 오름차순 정렬 후, wt 기준으로 내림차순 정렬 |
| > mtcars %>% arrange(wt) | > mtcars %>% arrange(mpg, desc(wt)) |
(4) 데이터 추가 및 중복 데이터 제거
| 열 추가 | 중복값 제거 |
| mutate(데이터, 추가할 변수명 = 조건1, ...) | distinct(데이터, 변수명) |
| > head(mutate(mtcars, years="1974")) → 맨 뒤에 years 열이 생성됨 |
> distinct(mtcars, cyl) → cyl 열에서 중복된 값을 제거함 |
(5) 데이터 요약
| 전체 요약 | 그룹별 요약 |
| summarise(데이터, 요약할 변수명 = 기술통계함수) | group_by(데이터, 변수명) |
| > summarise(mtcars, cyl_mean = mean(cyl), ...) cyl_mean 1 6.1875 > summarise(mtcars, mean(cyl), ...) mean(cyl) 1 6.1875 |
> gr_cyl <- group_by(mtcars, cyl) > summarise(gr_cyl, n()) # A tibble: 3 X 2 cyl 'n( )' <dbl> <int> 1 4 11 2 6 7 3 8 13 > summarise(gr_cyl, n_distinct(gear)) |
| > mtcars %>% summarise(cyl_mean = mean(cyl)) | > mtcars %>% group_by(cyl) %>% summarise(cyl_mean = mean(cyl)) |
(6) 데이터 추출
| 개수 기준 샘플 추출 | 비율 기준 샘플 추출 |
| sample_n(데이터, 추출할 샘플 개수) | sample_frac(데이터, 추출할 샘플 비율) |
| > sample_n(mtcars, 10) → 무작위 10개를 샘플로 추출 |
> sample_frac(mtcars, 0.2) → 전체의 20%를 샘플로 추출 |
(7) 파이프 연산자
- 새로운 변수에 저장하는 과정을 거치지 않고 데이터와 함수를 연결함
- 데이터 세트 %>% 조건 또는 계산 %>% 데이터 세트
> mutate(mtcars, mpg_rank = rank(mpg)) %>% arrange(mpg_rank)
→ mpg 기준으로 순위 계산/생성 후 정렬
2) 데이터 가공하기
(1) 데이터 결합
| 세로 결합 | 가로 결합 (by="변수명" 기준으로 결합) |
| bind_rows(테이블1, 테이블2) | left_join(테이블1, 테이블2, by="변수명") A∩Bⁿ inner_join(테이블1, 테이블2, by="변수명") A∩B full_join(테이블1, 테이블2, by="변수명") A∪B |
| > data_bindjoin <- bind_rows(data1, data2) > View(data_bindjoin) → 변수명 기준으로 결합함 |
> bind_col <- left_join(data1, data2, by="ID") → data1 기준으로 data2의 나머지 변수들을 결합 > bind_col_inner <- inner_join(data1, data2, by="ID") → 기준 변수값이 data1과 data2에서 동일한 것만 결합 > bind_col_full <- full_join (data1, data2, by="ID") → data1과 data2의 모든 변수들을 결합 |
3) 데이터 구조 변형하기
(1) melt( ) 함수: 열을 행으로 바꿈
- 넓은 모양의 데이터를 긴 모양으로 변형
- install.packages("reshape2") 패키지 설치 필요
- melt(데이터, id.vars="기준 열", measure.vars="변환 열")
> melt_data <- melt(airquality, id.vars=c("month", "wind"), measure.vars="ozone")
→ month, wind 변수를 식별자로 지정하고 ozone 값을 반환
(2) cast( ) 함수: 행을 열로 바꿈
- 긴 모양의 데이터를 넓은 모양으로 변형
| 데이터 프레임 형태로 반환 | 벡터, 행렬, 배열 형태로 반환 |
| dcast(데이터, 기준 열 ~ 변환 열) | acast(데이터, 기준 열 ~ 변환 열 ~ 분리 기준 열) |
| > dcast_data <- dcast(melt_data, month + day ~ variable) → month와 day를 식별자로 지정하고 variable 값 순서대로 변환 |
> acast(dcast_data, day ~ month ~ variable) → day와 month별로 항목이 분리되어 값 출력 |
| > dcast(melt_data, month ~ variable, sum) → 월별 변수들의 합계가 도출 |
> acast(melt_data, month ~ variable, mean) → 월별로 변수들의 평균 출력 |
4) 데이터 정제하기
(1) 결측치 확인
| 결측치 확인 | 결측치 빈도 확인 |
| is.na(변수명) | table(is.na(변수명)) |
| > x <- c(1, 2 NA, 4) > is.na(x) [1] FALSE FALSE TRUE FLASE |
> x <- c(1, 2 NA, 4) > table(is.na(x)) FLASE TRUE 3 1 |
| 결측치 총 개수 확인 | 컬럼별 결측치 개수 확인 |
| sum(is.na(변수명)) | colSums(is.na(변수명)) |
| > data(airquality) > sum(is.na(airquality)) [1] 44 |
> data(airquality) > colSums(is.na(airquality)) Ozone Wind Month Day 37 2 0 0 |
(2) 결측치 제거
| 결측치 제외하고 계산 | 결측치 있는 행 전체 제거 |
| na.rm = T 옵션 | na.omit(변수명) |
| > sum(x, na.rm = T) [1] 7 |
> na.omit(airquality) Ozone Wind Month Day 1 41 7.4 5 1 3 12 8.6 5 3 |
(3) 결측치 대체
| 결측치를 다른 값으로 대체 |
| 변수명[is.na(변수명)] <- 대체할 값 |
| > airquality[is.na(airquality)] <- 0 → 결측치를 0으로 대체 |
(4) 이상치 처리
- boxplot( ) 함수로 이상치를 확인함 (최고 경계값을 벗어난 값)
- ifelse(조건문, 조건이 참일 때 실행, 조건이 거짓일 때 실행)
> mtcars$wt <- ifelse(mtcars$wt > 5.25, NA, mtcars$wt)
→ 5.25 초과 값이면 NA로 변환
5주차. 기본 미션
p244의 확인 문제 2번 풀고 인증하기
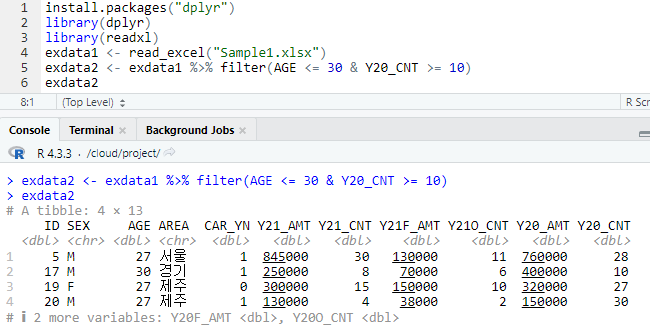
문2. 225쪽에서 가져온 exdata1 테이블에서 AGE가 30세 이하이면서 Y20_CNT가 10건 이상인 데이터를 exdata2 테이블로 생성하는 코드를 작성하여 실행 결과처럼 출력해 보세요. (파이프 연산자를 사용해 보세요.)
5주차. 선택 미션
p261의 확인 문제 4번 풀고 인증하기
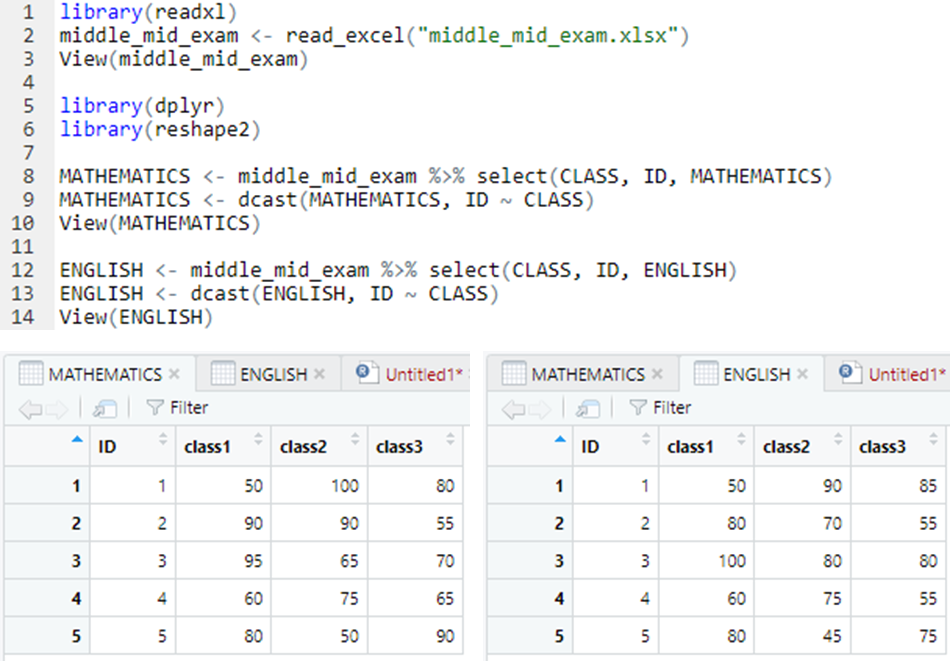
문4. 1학년 1반, 2반, 3반 학생 5명씩의 중간고사와 기말고사 성적이 기록된 엑셀 파일을 가져온 후 다음 실행 결과와 같이 반별 수학 점수와 영어 점수를 각각 출력해 보세요.