[빅데이터분석기사] 필기시험을 경험한 후에 요약한 자료입니다.
시험에 나온 문제! 시험에 나올법한 문제! 시험에 나왔으면 하는 문제!
최대한 시험 출제 유형과 유사한 내용들로 요약했으니,
이 자료로 공부하시는 모든 분들 합격하시길 바랍니다!
[목차]
Part4. 빅데이터 결과 해석
Part4-1. 분석모형 평가 및 개선
1. 분석모형 평가
2. 분석모형 개선
Part4-2. 분석결과 해석 및 활용
1. 분석결과 해석
2. 분석결과 시각화
Part4-1. 분석모형 평가 및 개선
1. 분석모형 평가
1) 평가 지표
(1) 회귀모형 평가 지표
- 평균절대오차, 평균제곱오차, 평균제곱근오차, 평균절대백분율오차
- 결정계수(R²=1 → 설명력↑)
(2) 분류모형 평가 지표
※ 혼동행렬
| 구분 | 예측값 | 평가항목 | ||
| 참(P) | 거짓(N) | |||
| 실제값 | 참(P) | TP | FN (2종 오류) | 민감도(Sensitivity) |
| 거짓(N) | FP (1종 오류) | TN | 특이도(Specificity) | |
| 평가항목 | 정밀도(Precision) | - | 정확도(Accuracy) | |
※ 평가지표
| 정확도(Accuracy) | 민감도(Sensitivity) | 특이도(Specificity) | 정밀도(Precision) |
| = TP+TN / TP+TN+FP+FN |
= TP / TP+FN | = TN / TN+FP | = TP / TP+FP |
| - | = 재현율(Recall) = 참 긍정률(TPR) |
거짓 긍정률(FPR) = 1 - 특이도 |
- |
- F1 Score = 2 X { (민감도X정밀도) / (민감도+정밀도) }
(3) ROC 곡선
- AUC는 곡선 아래 면적으로, AUC = 1일수록 성능 좋음

2) 분석모형 진단
(1) 회귀모형 진단
| 가정 | 내용 | 진단방법 |
| 선형성 | - 종속변수는 독립변수의 선형함수 | - 잔차산점도 선형성 |
| 독립성 | - 독립변수 간 상관관계 X | - 잔차산점도 경향성 X - 더빈왓슨 검정 |
| 등분산성 | - 오차항의 분산 = 등분산 | - 잔차산점도 고르게 분포 |
| 정규성 | - 오차항의 평균 = 0 | - 사피로 월크 검정 - 콜모고로프-스미르노프 적합성 검정 - Q-Q plot |
(2) 분석모형 오류
| 일반화 오류 (과대적합) | 학습 오류 (과소적합) |
| 학습데이터 특성을 지나치게 반영 | 학습데이터 특성을 부족하게 반영 |
| 편향↓, 분산↑ 학습데이터는 좋은 성능 검증데이터는 낮은 성능 |
복잡도는 낮음 학습/검증데이터 모두 낮은 성능 |
3) 교차 검증
| K-fold 교차검증 | Hold-out 교차검증 | Leave-P-Out 교차검증 |
| 학습데이터 k-1개 검증데이터 나머지 1개 |
무작위 7:3 or 8:2 | 검증데이터 P개 학습데이터 나머지 n-p개 |
4) 모수의 유의성 검증
| 모수 검정 | 비모수 검정 |
| 모집단의 분포를 가정 집단 간 차이 검정 |
① 모집단이 특정 분포를 가정하지 않는 경우 ② n=30 미만인 경우 ③ 서열/명목척도인 경우에 사용 |
| 검정통계량: 표본평균, 표준편차 검정력: 모수 > 비모수 검정 |
검정통계량: 순위, 부호 |
| 모집단에 대한 유의성 검증 | ||||
| Z-검정 | 분산분석(ANOVA) | T-검정 | 카이제곱 검정 | F-검정 |
| 표본이 모집단에 속하는지 검증 |
집단의 평균 비교 | 단일: 평균 검증 양측: 평균 비교 |
(분산 알 때) 집단의 동질성 검정 |
분산 차이 유의성 검정 |
5) 적합도 검증
(1) Q-Q plot
- 정규분포에 얼마나 가까운지 시각적으로 표현
(2) 카이제곱 검정
- 독립인지 아닌지 확인, 범주형데이터에 사용, rxc분할표 사용
- 적합성 검정, 독립성 검정, 동일성 검정
- H0: "정규분포를 따른다", p-value=0.0026
☞ p-value < 0.05 → 귀무가설 기각함 → "정규분포를 따르지 않는다"
(3) 샤피로 윌크 검정
- 정규성 검증
(4) 콜모고로프 스미르노프 검정
- 예상 분포와 얼마나 잘 맞는지 검정
- 누적 분포함수를 비교, 연속형데이터 적용 가능
2. 분석모형 개선
1) 과대적합 방지
① 학습데이터 수 증가
- 추가데이터 확보 필요 (오버샘플링, 언더샘플링 사용)
② 가중치 규제
- 가중치 값을 제한하여 변수의 수를 줄이는 효과 (과대적합 문제 해결)
- 예) L1규제, L2규제
③ 교차 검증
- 다른 검증데이터를 사용
2) 매개변수 최적화
(1) 경사하강법
- 손실함수의 기울기를 통해 최적값을 구하는 방법
- 기울기=0일때, 손실함수가 최소화되는 매개변수 값이 됨 (전역 최솟값)
| 배치 경사하강법(BGD) | 확률적 경사하강법(SGD) | 미니 배치 경사하강법 |
| 전체 데이터 사용 | 무작위 1개 선택 | 무작위 10~1000개 선택 |
| 부드럽게 수렴 시간 오래 걸림 |
오차율 크고, 불안정하게 수렴 속도 빠름 |
BGD보다 빠름 SBD보다 오차율 낮음 |
(2) 모멘텀
- 확률적 경사하강법의 매개변수 변경방향에 가속도 부여
- 모멘텀 계수(α)는 하이퍼파라미터로 0.9로 설정
(3) AdaGrad
- 변수마다 학습률을 다르게 적용
- 값이 많이 변한 매개변수 → 학습률↓
* 학습률: 매개변수가 변경되는 폭
(4) RMSProp
- AdaGrad 개선된 방법
- 하이퍼파라미터(ρ) 값↓ → 최근 기울기 더 많이 반영
(5) Adam = 모멘텀 + RMSProp
- 매개변수 변경방향 + 폭, 모두 적절히 조절 가능
3) 분석모형 융합 (앙상블 기법)
| 보팅(Voting) | 배깅(Bagging) | 부스팅(Boosting) | 스태킹(Stacking) |
| 여러 분석모형 결과를 종합 |
Bootstrap 샘플을 무작위 복원 추출해 최종 분석모형 도출 |
약한 분석모형 여러개 연결하여 강한 분석모형 도출 |
여러 분석모형 예측을 종합 |
| Hard voting(직접) : 많이 선택된 class Soft voting(간접) : class 확률값의 평균 |
과대적합↓, 분산↓ | 정답에 낮은 가중치, 오답에 높은 가중치 |
- |
| - | 예) Random Forest | 예) Adaboost, XGboost, Light GBM |
Blender, Meta learner 사용 |
- 페이스팅(Pasting): 배깅과 동일하지만, 중복 허용 X
Part4-2. 분석결과 해석 및 활용
1. 분석결과 해석
1) 분석모형 해석
| 해석 가능한 모형 | 순열 변수 중요도 | 부분 의존도 plot |
| : 간단, 직관적, 학습시간 짧음 : 예측 정확도 낮음 |
: 변수의 중요도 파악 : 대표적인 변수 중요도 방법 |
: 중요변수를 1~2개 선택 후, 어떤 영향을 미치는지 확인 |
| 예) 선형회귀, 로지스틱 회귀, 의사결정나무 |
예) 랜덤포레스트 모형 | - |
2) 비즈니스 기여도 평가
| 투자대비 효과 (ROI) | 순 효과를 총 비용으로 나눈 값 |
| 순현재가치 (NPV) | 편익의 현재가치 - 비용의 현재가치 순현재가치 > 0 → 타당성 있는 사업 |
| 내부수익률 (IRR) | 순현재가치 = 0으로 만드는 할인율 IRR > 요구수익률 → 투자 적합 |
| 총 소유비용 (TCO) | 자산 획득 시의 비용 + 제반비용 등 총 비용 |
| 투자회수 기간 (PP) | 흑자로 돌아서는 시점까지의 기간 |
2. 분석결과 시각화
1) 시각화 분류
| 데이터 시각화 | 정보 시각화 | 정보 디자인 |
| 예) 마인드맵, 뉴스 표현 | 예) 분기도, 수지도, 히트맵 | 예) 데이터 시각화, 정보 시각화, 인포그래픽 |
2) 시각화 종류
(1) 시간 시각화
| 이산형 | 연속형 | |||
| 막대 그래프 | 산점도 | 선 그래프 | 계단식 그래프 | 영역차트 |
| 범주별 데이터 값 | 두 변수의 관계 | 관측치(점)을 선으로 표시 |
x축과 평행한 선으로 연결 |
그래프 안 영역을 색으로 칠한 형태 |
 |
 |
 |
 |
 |
(2) 공간 시각화
| 등치지역도 | 도트 플롯 맵 | 버블 플롯 맵 | 등치선도 | 카토그램 |
| 지리적 단위 기준 색상으로 구분 |
위도/경도 좌표점 |
위/경도 좌표점 + 데이터 값 |
지리적 위치를 선으로 이어 |
지역 크기를 조정 |
 |
 |
 |
 |
 |
(3) 관계 시각화
| 산점도 | 산점도 행렬 | 버블 차트 | 히스토그램 |
| 두 변수의 관계 | 다변량 데이터 모든 수치형 변수 간의 산점도 |
버블 크기/모양으로 표기 | 도수분포를 막대 형태로 표기 |
 |
 |
 |
 |
(4) 비교 시각화
| 히트맵 | 스타차트 | 채르노프 페이스 | 평행좌표 그래프 |
| 칸 색상으로 표기 행은 관측치, 열은 변수 |
여러 변수를 각각 축, 중앙으로의 거리를 값 |
변수 값을 얼굴부위에 대응 |
y축에 평행한 여러 개의 축으로 데이터 표현 |
| 관측치/변수↑ → 부적합 |
= 레이더 차트 = 방사형 차트 여러관측치 비교 쉬움 |
관측치 특성을 알아보기 쉬움 |
데이터 패턴 및 그룹별특성 파악 쉬움 |
 |
 |
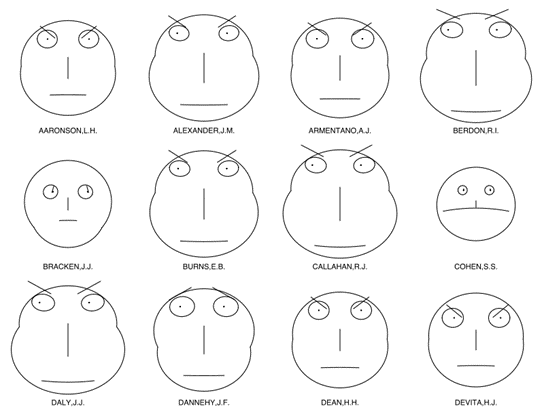 |
 |
(5) 인포그래픽
- 그래픽으로 이해하기 쉽게 표현
- Raw data 취급 X
- 정보형 메시지(지하철 노선도), 설득형 메시지를 포함
※ 자세한 내용은 아래 자료를 참고 부탁드립니다.
[빅데이터분석기사/필기요약] Part4-1. 분석모형 평가 및 개선
[빅데이터분석기사]의 필기시험 요약자료로 Part4. 빅데이터 결과 해석의 "Chapter1. 분석모형 평가 및 개선"입니다. 출제 빈도가 높은 내용 위주로 요약했으니, 이 자료로 공부하시는 모든 분들 합
dataslog.tistory.com
[빅데이터분석기사/필기요약] Part4-2. 분석결과 해석 및 활용
[빅데이터분석기사]의 필기시험 요약자료로 Part4. 빅데이터 결과 해석의 "Chapter2. 분석결과 해석 및 활용"입니다. 출제 빈도가 높은 내용 위주로 요약했으니, 이 자료로 공부하시는 모든 분들 합
dataslog.tistory.com
'빅데이터 분석기사 > 필기 요약' 카테고리의 다른 글
| [빅데이터분석기사/필기요약] Part3.빅데이터 모델링 (0) | 2023.04.18 |
|---|---|
| [빅데이터분석기사/필기요약] Part2. 빅데이터 탐색 (2) | 2023.04.17 |
| [빅데이터분석기사/필기요약] Part1.빅데이터 분석기획 (0) | 2023.04.16 |
| [빅데이터분석기사/필기후기] 제6회 필기시험 후기(기출문제) (0) | 2023.04.09 |
| [빅데이터분석기사/필기요약] Part4-2. 분석결과 해석 및 활용 (0) | 2023.04.06 |