7. 프로젝트로 실력 다지기
1) 지역별 국내 휴양림 분포 비교하기
2) 해외 입국자 추이 확인하기
3) 지도에서 코로나19 선별진료소 위치 확인하기
4) 서울시 지역별 미세먼지 농도 차이 비교하기
1) 지역별 국내 휴양림 분포 비교하기
> library(readxl)
> forest_example_data <- read_excel("forest_example_data.xls")
> colnames(forest_example_data) <- c("name", "city", "gubun", "area", "number", "stay", "city_new", "code", "codename")
> str(forest_example_data) # 데이터 속성 확인

> head(forest_example_data) # 데이터 일부 확인

> library(descr)
> freq(forest_example_data$city, plot=T, main='city') # 시도별 휴양림 빈도분석
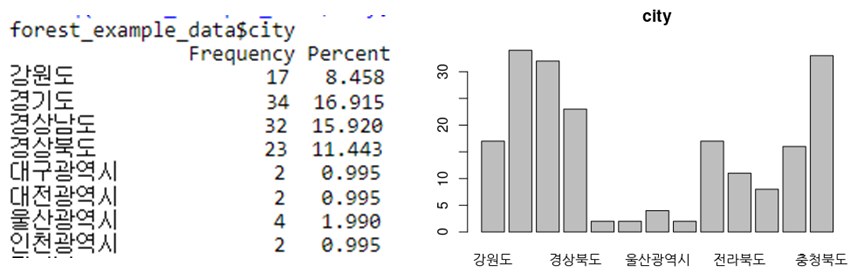
> library(dplyr)
> count(forest_example_data, city) %>% arrange(desc(n)) # 내림차순 정렬

2) 해외 입국자 추이 확인하기
(1) 데이터 가공
- gsub("찾을 문자열", "대체할 문자열", 데이터) 함수: 찾기 바꾸기 기능
> entrance_data$country <- gsub(" ", "", entrance_data$country) # 띄어쓰기 제거
- nrow( ) 함수: 행 개수 확인
> entrance_data |> nrow() # 행 개수 확인
[1] 67
- order( ) 함수: 오름차순 정렬
- order( decreasing=T) ) 함수: 내림차순 정렬 (= 변수 앞 - 기호)
- |> 기호: 네이티브 파이프 연산자 (%>%와 같은 의미)
> entrance_data[order(-entrance_data$JAN),] |> head(n=5) # 상위 5개국 추출

> library(reshape2)
> top5_melt <- melt(top5_country, id.vars='country', variable.name='mon')
> head(top5_melt)

(2) 데이터 시각화
- ggtitle( ) 함수: 그래프 제목
- scale_y_continuous( ) 함수: y축 범위 조정
- seq(시작값, 끝값, 간격) 함수: 축 범위 값 지정
> library(ggplot2)
> ggplot(top5_melt, aes(x=mon, y=value, group=country)) + geom_line(aes(color=country)) + ggtitle("2020년 국적별 입국 수 변화 추이") + scale_y_continuous(breaks=seq(0, 500000, 50000))

- fill 옵션: 막대 안 색상 / color 옵션: 막대 테두리 색상
- stat 옵션: y축 데이터를 그릴 경우 / position 옵션: 막대 유형(dodge는 개별 막대)
> ggplot(top5_melt, aes(x=mon, y=value, fill=country)) + geom_bar(stat="identity", position="stack")

3) 지도에서 코로나19 선별진료소 위치 확인하기
> jeju_data <- data_raw[data_raw$state=="제주",] # 제주 데이터 추출
- mutate_geocode(data=데이터 프레임명, location=주소 열 이름, source='google) 함수: 주소별 경도와 위도 데이터를 가져옴
> jeju_data_loc <- mutate_geocode(data=jeju_data, location=addr, source='google')
> jeju_map <- get_googlemap('제주', maptype='roadmap')
> ggmap(jeju_map) + geom_point(data=jeju_data_loc, aes(x=lon, y=lat, color=factor(name)), size=3)

- marker 옵션: 지도 위에 마커 형태로 표시
- geon_text( ) 함수: 지도 위에 레이블 표기
> jeju_data_marker <- data.frame(jeju_data_loc$lon, jeju_data_loc$lat)
> jeju_marker_map <- get_googlemap('제주', maptype='roadmap', markers=jeju_data_marker)
> ggmap(jeju_marker_map) + geom_text(data=jeju_data_loc, aes(x=lon, y=lat), size=3, label=jeju_data_loc$name)

4) 서울시 지역별 미세먼지 농도 차이 비교하기
> library(dplyr)
> dustdata_data <- dustdata[, c("날짜", "강남구", "성동구")] # 특정 데이터 추출
> sum(is.na(dustdata_data)) # 결측치 개수 확인
[1] 0
- describe( ) 함수: 기술통계량 분석
> library(psych)
> describe(dustdata_data$강남구)
vars n mean sd median trimmed mad min max range skew kurtosis se
X1 1 31 33.03 16.94 31 30.84 13.34 8 85 77 1.19 1.37 3.04
> boxplot(dustdata_data$강남구, dustdata_data$성동구, main="finedust_compare", xlab="AREA", ylab="FINEDUST_PM", names=c("강남구", "성동구"), col=c("green", "orange"))

| f-검정 (두 집단 간의 분산에 차이가 있는지 확인) |
T-검정 (두 집단 간의 평균 차이가 있는지 확인) |
| var.test(데이터1, 데이터2) | t.test(data=테이블명, 변수2~변수1, var.equal=T) |
| > var.test(dustdata_data$강남구, dustdata_data$성동구) F test to compare two variances data: dustdata_data$강남구 and dustdata_data$성동구 F = 0.9496, num df = 30, denom df = 30, p-value = 0.8883 → p-value 값이 0.05보다 크므로 귀무 가설을 기각할 수 없음 → 즉, 두 집단 간 분산 차이는 없음 |
> t.test(dustdata_data$강남구, dustdata_data$성동구, var.equal=T) Two Sample t-test data: dustdata_data$강남구 and dustdata_data$성동구 t = -0.28118, df = 60, p-value = 0.7795 → p-value 값이 0.05보다 크므로 통계적으로 유의하지 않음 →즉, 두 집간 간 평균 차이가 없음 |
'혼공학습단 > 혼자 공부하는 R 데이터 분석' 카테고리의 다른 글
| [혼공R이] 12기 마무리하며♡ (0) | 2024.08.18 |
|---|---|
| [혼공R이] #6. 데이터 시각화 (0) | 2024.08.12 |
| [혼공R이] #5. 데이터 가공하기 (0) | 2024.08.05 |
| [혼공R이] #4. 데이터 다루기 (1) | 2024.07.22 |
| [혼공R이] #3. R 프로그래밍 익히기 (1) | 2024.07.20 |