3. 데이터 정제하기
2) 잘못된 데이터 수정하기
(1) 데이터프레임 정보 요약 확인하기
(2) 누락된 값 처리하기
(3) 정규 표현식
(4) 잘못된 값 바꾸기
(5) 누락된 정보 채우기
2) 잘못된 데이터 수정하기
(1) 데이터프레임 정보 요약 확인하기
- 도서명은 누락된 값이 403개임 (=384591-384188)
RangeIndex: 384591 entries, 0 to 384590 # 전체 행 개수
Data columns (total 13 columns): # 열 개수
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 번호 384591 non-null int64 # 누락된 값이 없는 행 개수
1 도서명 384188 non-null object
2 저자 384393 non-null object
...
dtypes: float64(1), int64(2), object(10) # 데이터 타입
memory usage: 38.1+ MB # 메모리 사용량
(2) 누락된 값 처리하기
① 누락된 값 개수 확인하기
- [isna() 메서드]는 누락된 값을 True로 반환해 주며, sum() 메서드와 같이 사용하여 누락된 값이 있는 행 개수를 확인함
도서명 403
저자 198
출판사 4641
발행년도 14
ISBN 0
세트 ISBN 328015
부가기호 74205
권 321213
주제분류번호 19864
도서권수 0
대출건수 0
등록일자 0
dtype: int64
- [notna() 메서드]는 누락되지 않은 값을 확인할 때 사용함
② 누락된 값으로 표시하기
- '도서권수'(정수형) 열의 첫 번째 행 값을 임의로 None으로 변경함 → NaN으로 출력됨

- '부가기호'(문자형) 열의 첫 번째 행 값을 임의로 None으로 변경함 → None로 출력됨

- NaN으로 출력하기 위해서는 넘파이 패키지의 [np.nan]을 사용해야 함
- [astype() 메서드]로 데이터 타입을 변경하며, 매개변수는 {열 이름: 데이터 타입}의 딕셔너리 형식임
③ 누락된 값을 원하는 값으로 바꾸기
- [loc 메서드]로 누락된 값(NaN) → '없음'으로 변경
- [fillna() 메서드]에 원하는 값을 전달하면 NaN 값을 대체함
- [replace() 메서드]는 어떤 값도 바꿀 수 있으며, replace(원래 값, 원하는 값) 형태로 사용함
- [replace() 메서드]로 여러 개의 값을 바꿀 때는, replace([원래 값1, 원래 값 2], [원하는 값1, 원하는 값2]) 형태로 사용함

- [replace() 메서드]로 열 마다 다른 값으로 바꿀 때는, replace({열 이름: {원래 값, 원하는 값}}) 형태로 사용함
(3) 정규 표현식 (= 정규식)
- 문자열에서 패턴을 찾고 대체하기 위한 규칙의 모음
① 숫자 찾기
- 정규 표현식에서 숫자는 \d이며, \d\d(\d\d)는 네 자리 숫자에 뒤에 두 자리를 하나의 그룹으로 묶음을 의미함
- replace() 메서드에 [regex 매개변수]를 True로 지정하여 정규 표현식을 사용함을 의미함
- [r문자]는 정규 표현식을 사용한다는 접두사를 의미함
- 2021 → 21로의 변환은 \d\d(\d\d) 패턴 안에 있는 첫 번째 그룹으로 변환해 준다는 형태로 사용함

② 문자 찾기
- [.]은 문자를 의미하며, 글자 수 동일하지 않을 경우 [*]을 사용하여 0개 이상 반복됨을 의미함
- 문자로 인식하려면 앞에 [\]를 붙여야 하고, 공백은 [\s]로 표시함
- 'AB CDE (지은이), 가나다 (옮긴이)' → 'AB CDE, 가나다' 형태로 변환하기 위한 정규 표현식은 아래와 같음

ns_book4.replace({'저자': {r'(.*)\s\(지은이\)(.*)\s\(옮긴이\)': r'\1\2'}, regex=True)[100:102]

(4) 잘못된 값 바꾸기
① 잘못된 값 찾기 (문자가 포함된 값)
- 다른 모든 문자에 대응하는 표현은 \D임
- [contains() 메서드]는 주어진 문자열 포함된 모든 행을 찾음 (1988., 1988-02-05 등)
- [na 매개변수]를 True로 지정하여 값이 누락된 행을 True로 표시
- 발행년도에 문자가 포함된 행 및 공란인 행을 출력함
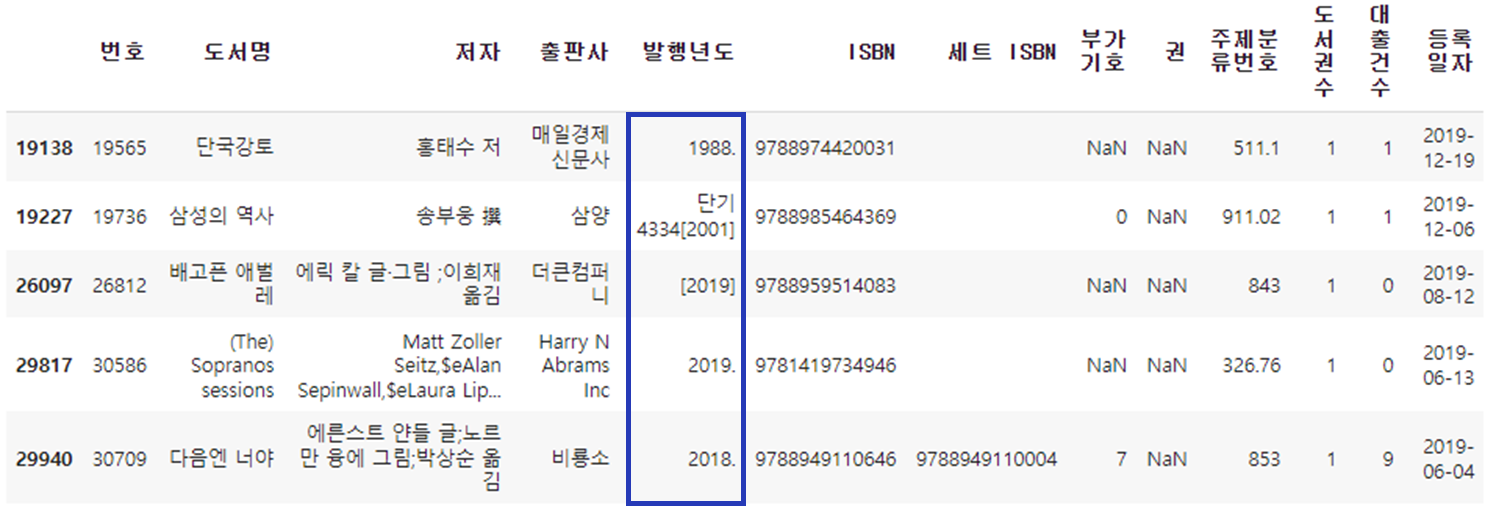
② 잘못된 값 바꾸기 (연도 외 정보 삭제)
- 정규 표현식으로 연도 앞/뒤 문자를 제외 (즉, 숫자 4자리만 남겨둠)
- 연도가 없는 행을 출력함 (즉, 여전히 문자가 포함된 행을 출력함)
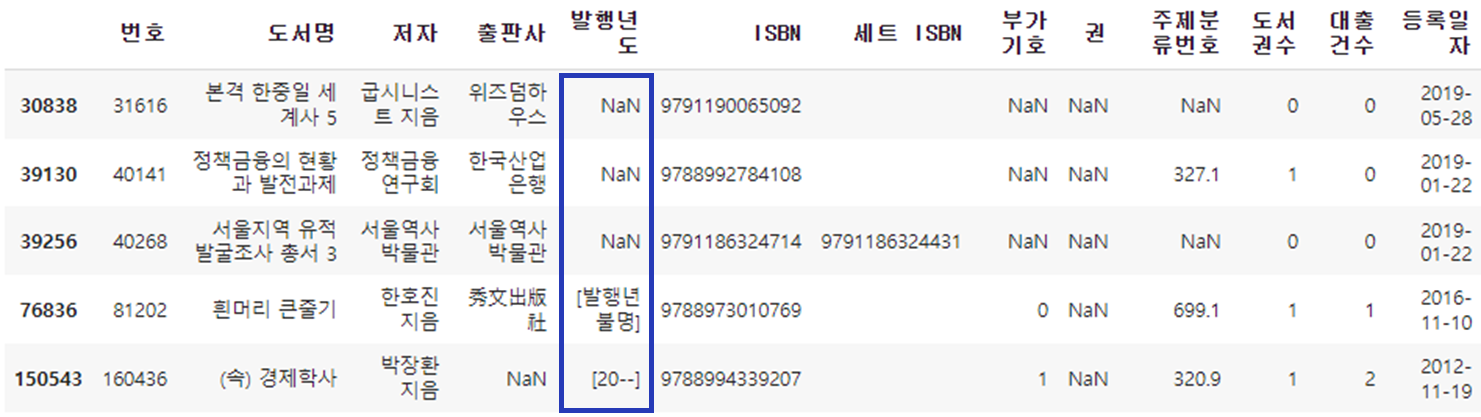
- 여전히 문자가 포함된 행을 '-1'로 변경함
③ 이상치 값 바꾸기
- '발행년도'가 4000 이상인 경우, 2333을 빼서 서기 연도로 바꿔줌
- 여전히 4000 이상인 행을 '-1'로 변경함
- '발행년도'가 0 ~ 1900년 사이인 행을 '-1'로 변경함
- '발행년도' 값이 정상적이지 않은 행 개수 출력함
(5) 누락된 정보 채우기
- '도서명', '저자', '출판사' 열에 누락된 값을 외부 정보로 채우기

3주차. 기본 미션
p182. 확인 문제 2번 풀고 인증하기
문2. 1번 문제의 df 데이터프레임에서 'col1' 열의 합을 계산하는 명령으로 올바르지 않은 것은 무엇인가요?
| col1 | col2 | col3 | |
| 0 | 1 | a | NaN |
| 1 | 2 | NaN | NaN |
| 2 | 3 | c | 100.0 |
① df['col1'].sum()
② df[['col1']].sum()
③ df.loc[:, df.columns == 'col1'].sum()
④ df.loc[:, [False,False,True]].sum()
→ 정답 ④ 'col3' 열의 합을 계산함
3주차. 선택 미션
p219. 확인 문제 5번 풀고 인증하기
문5. 다음과 df 데이터프레임에서 df.replace(r'ba.*', 'new', regex=True)의 결과는 무엇인가요?
| <df> | A | B |
| 0 | abc | |
| 1 | foo | new |
| 2 | new |
xyz |
→ 정답 ① ba로 시작하는 단어가 모두 'new'로 변경됨
[혼공분석] #3-1. 불필요한 데이터 삭제하기
3. 데이터 정제하기 1) 불필요한 데이터 삭제하기 1-1) 열 삭제하기 (1) 불리언 배열 (2) drop() 메서드 (3) dropna() 메서드 1-2) 행 삭제하기 (1) 불리언 배열 (2) drop() 메서드 (3) 중복된 행 찾기, duplicated()
dataslog.tistory.com
'혼공학습단 > 혼자 공부하는 데이터 분석 with 파이썬' 카테고리의 다른 글
| [혼공분석] #5. 데이터 시각화하기 (1) | 2024.02.04 |
|---|---|
| [혼공분석] #4. 데이터 요약하기 (1) | 2024.01.28 |
| [혼공분석] #3-1. 불필요한 데이터 삭제하기 (0) | 2024.01.20 |
| [혼공분석] #2-2. 웹 스크래핑으로 데이터 수집하기 (0) | 2024.01.14 |
| [혼공분석] #2-1. API로 데이터 수집하기 (1) | 2024.01.14 |