2. 데이터 수집하기
1) API 사용하기
(1) API란
(2) JSON 다루기
(3) XML 데이터 다루기
(4) API 호출하기
1) API 사용하기
(1) API란
- API: 프로그램 간 데이터를 전달하기 위해 정한 규칙, 데이터베이스 접근 권한이 복잡한 데이터 접근 시 API를 사용
- HTTP: 웹에서 데이터를 주고받기 위한 프로토콜
- 웹 기반 API에는 JSON, XML을 많이 사용함
 웹 기반 API
웹 기반 API
(2) JSON 데이터 다루기
- JSON: 데이터 전달 포맷, 읽기 편하고 간단하게 파이썬 객체로 변환할 수 있는 것이 장점
① {"키": "값"}
- JSON 형식의 파이썬 딕셔너리 생성하기
d = {"name": "혼자 공부하는 데이터 분석"} # "키": "값"
print(d['name'])
혼자 공부하는 데이터 분석
② json.dumps() 함수
- 파이썬 객체를 JSON 형식의 문자열로 변환하기
- 한글이 포함되어 있으면, ensure_ascii 매개변수 활용
import json
d_str = json.dumps(d, ensure_ascii=False)
print(d_str)
{"name": "혼자 공부하는 데이터 분석"}
③ json.loads() 함수
- JSON 문자열을 파이썬 객체로 변환하기
d2 = json.loads(d_str)
print(d2['name'])
혼자 공부하는 데이터 분석
d3 = """
[
{"name": "혼자 공부하는 데이터 분석", "author": "박해선", "year": 2022},
{"name": "혼자 공부하는 머신러닝+딥러닝", "author": ["박해선","홍길동"], "year": 2019}
]
"""
d4 = json.loads(d3)
print(d4[0]['name'])
print(d4[1]['author'][1])
print(d4[1]['year'])
혼자 공부하는 데이터 분석
홍길동
2019
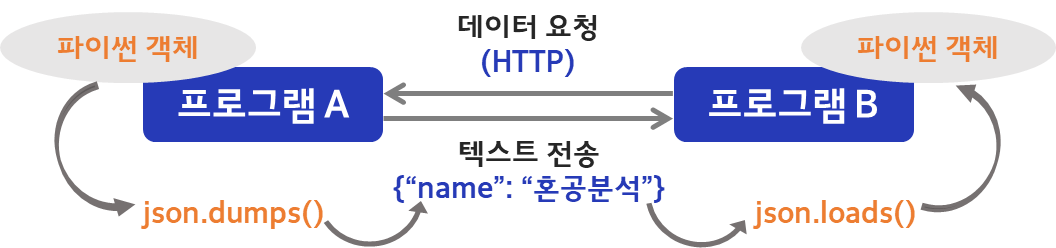 파이썬 객체 ↔ JSON 문자열
파이썬 객체 ↔ JSON 문자열
④ read_json() 함수
- JSON 문자열을 데이터프레임으로 변환하기
import pandas as pd
pd.read_json(d3) # =pd.DataFrame(d4)
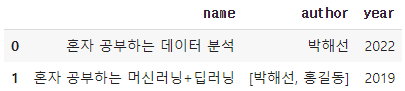 read_json() 결과
read_json() 결과
(3) XML 데이터 다루기
- XML: 엘리먼트(시작 태그와 종료 태그로 감싼 형태)들이 계층 구조를 이룬 형태
① fromstring() 함수
- XML 문자열을 파이썬 객체로 변환하기
- 시작 태그와 종료 태그의 이름은 동일해야 함
- 아래 코드는 <book> 부모 엘리먼트(노드)의 자식 엘리먼트 <name>, <author>, <year>로 구성됨
x_str = """
<book>
<name>혼자 공부하는 데이터 분석</name>
<author>박해선</author>
<year>2022</year>
</book>
"""
import xml.etree.ElementTree as et
book = et.fromstring(x_str)
print(type(book))
<class 'xml.etree.ElementTree.Element'>
② findtext() 메서드
- 자식 엘리먼트 확인하기
- findtext() 메서드가 자식 엘리먼트를 자동으로 탐색하여 해당 엘리먼트로 매칭함
book_childs = list(book)
print(book_childs)
[<Element 'name' at 0x79f529f98810>, <Element 'author' at 0x79f529f987c0>, <Element 'year' at 0x79f529f9b0b0>]
name = book.findtext('name')
author = book.findtext('author')
year = book.findtext('year')
print(name)
print(author)
print(year)
혼자 공부하는 데이터 분석
박해선
2022
③ findall() 메서드와 for문
- 여러 개의 자식 엘리먼트 확인하기
x2_str = """
<books>
<book>
<name>혼자 공부하는 데이터 분석</name>
<author>박해선</author>
<year>2022</year>
</book>
<book>
<name>혼자 공부하는 머신러닝+딥러닝</name>
<author>박해선, 홍길동</author>
<year>2019</year>
</book>
</books>
"""
books = et.fromstring(x2_str)
for book in books.findall('book'):
name = book.findtext('name')
author = book.findtext('author')
year = book.findtext('year')
print(name)
print(author)
print(year)
print()
혼자 공부하는 데이터 분석
박해선
2022
혼자 공부하는 머신러닝+딥러닝
박해선, 홍길동
2019
import pandas as pd
pd.read_xml(x2_str)
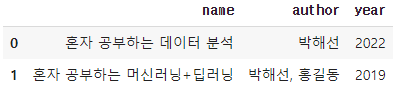 read_xml() 결과
read_xml() 결과
(4) API 호출하기
① API를 호출하는 URL 작성
| HTTP GET 방식 |
| = 문자 |
& 문자 |
? 문자 |
| 파라미터와 값 |
파라미터와 파라미터 |
호출 URL과 파라미터 |
 호출 URL
호출 URL
② requests 패키지
- 파이썬으로 API 호출하기
import requests
r = requests.get(url)
data = r.json()
print(data)
data
{'response': {'request': {'startDt': '2021-04-01', 'endDt': '2021-04-30', 'age': '20', 'pageNo': 1, 'pageSize': 200}, 'resultNum': 200, 'numFound': 5000, 'docs': [{'doc': {'no': 1, 'ranking': '1', 'bookname': '우리가 빛의 속도로 갈 수 없다면 :김초엽 소설 ',
{'response': {'request': {'startDt': '2021-04-01',
'endDt': '2021-04-30',
'age': '20',
'pageNo': 1,
'pageSize': 200},
'resultNum': 200,
'numFound': 5000,
'docs': [{'doc': {'no': 1,
'ranking': '1',
'bookname': '우리가 빛의 속도로 갈 수 없다면 :김초엽 소설 ',
'authors': '지은이: 김초엽',
'publisher': '허블',
'publication_year': '2019',
'isbn13': '9791190090018',
'addition_symbol': '03810',
'vol': '',
'class_no': '813.7',
'class_nm': '문학 > 한국문학 > 소설',
'loan_count': '487',
'bookImageURL': 'https://image.aladin.co.kr/product/19359/16/cover/s972635417_1.jpg',
'bookDtlUrl': 'https://data4library.kr/bookV?seq=5430429'}},
{'doc': {'no': 2,
'ranking': '2',
'bookname': '달러구트 꿈 백화점 :이미예 장편소설',
③ 데이프레임 출력
- 딕셔너리 구조를 변경하여 데이터프레임 형태로 출력하기
books = []
for d in data ['response']['docs']:
books.append(d['doc'])
# books = [d['doc] for d in data['response']['docs']]
books_df = pd.DataFrame(books)
books_df
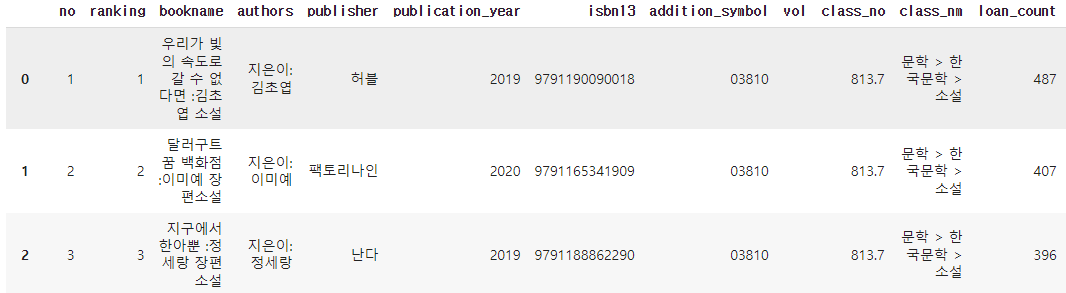 API 호출 데이터프레임 결과
API 호출 데이터프레임 결과
④ to_json() 메서드
- JSON 파일로 저장
books_df.to_json('20s_best_book.json')
[혼공분석] #2-2. 웹 스크래핑으로 데이터 수집하기
2. 데이터 수집하기 2) 웹 스크래핑 사용하기 (1) 웹 크롤링 (2) 검색 결과 페이지 가져오기 (3) HTML 찾기 (4) 뷰티플수프 (5) 여러 도서 쪽수 정보 찾기 2) 웹 스크래핑 사용하기 (1) 웹 크롤링 (= 웹 스
dataslog.tistory.com