2. 데이터 수집하기
2) 웹 스크래핑 사용하기
(1) 웹 크롤링
(2) 검색 결과 페이지 가져오기
(3) HTML 찾기
(4) 뷰티플수프
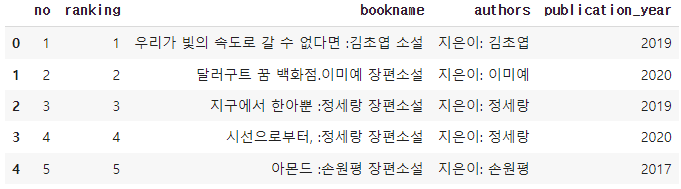
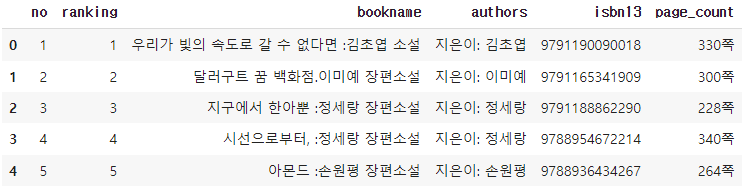
(5) 여러 도서 쪽수 정보 찾기
2) 웹 스크래핑 사용하기
(1) 웹 크롤링 (= 웹 스크래핑)
- 웹사이트의 페이지를 옮겨 가며 데이터를 추출하는 작업
- requests 패키지로 웹사이트 HTML에서 데이터를 추출
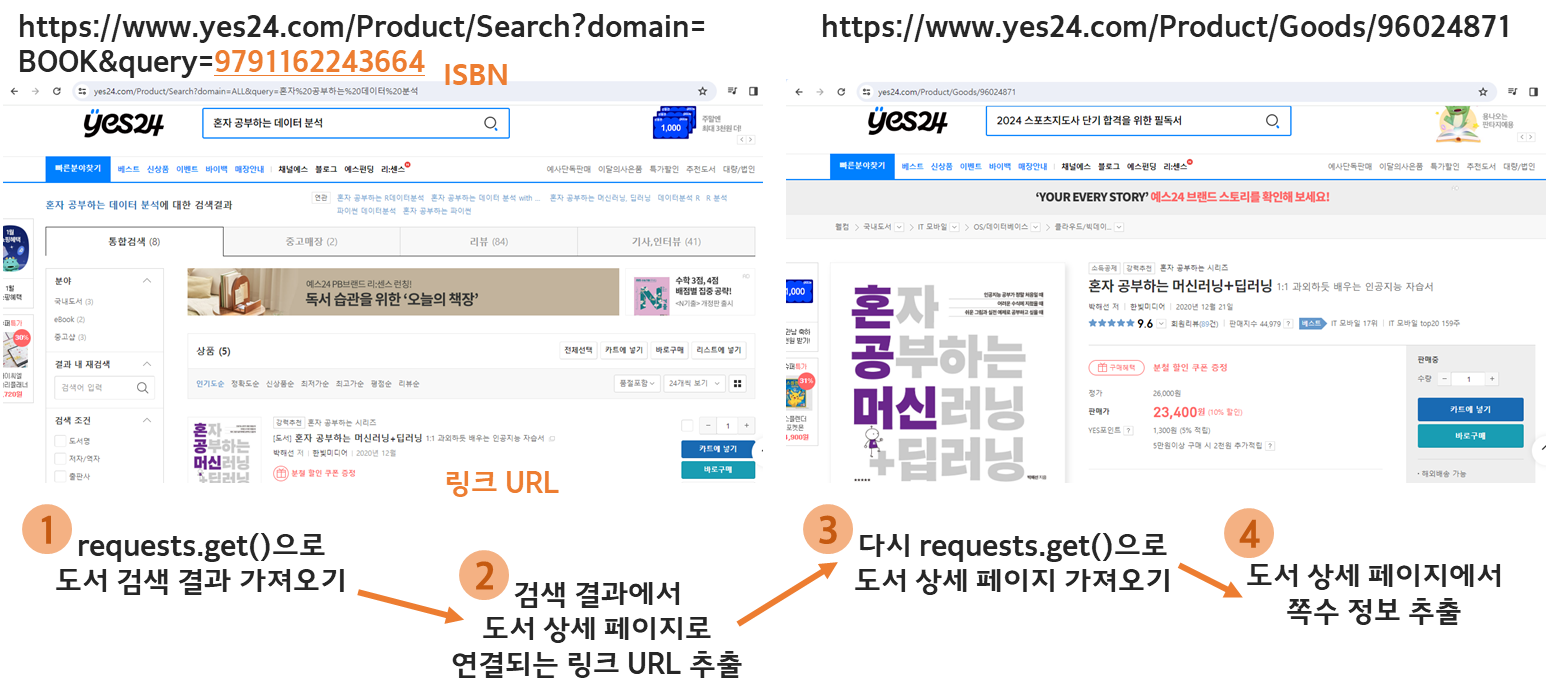
- 예) YES24에서 도서 쪽수 웹 크롤링 과정
※ 웹 크롤링 주의사항
- 웹사이트에서 스크래핑을 허락했는지 확인 (robots.txt 확인)
- HTML 태그를 특정할 수 있는지 확인
- 디자인이 자주 변경되는지 확인
(2) 검색 결과 페이지 가져오기
① 특정 열 선택
- 원하는 열 이름을 리스트로 만들어 데이터프레임의 인덱스처럼 사용
② loc 메서드
- 대괄호를 사용하여 행과 열의 목록 지정
* loc 메서드의 슬라이싱은 파이썬과 달리 마지막 항목도 포함함
(3) HTML 찾기
① 개발자 도구로 HTML 태그 찾기
- 웹사이트 마우스 오른쪽 클릭 → 검사 클릭
- F12 키
② requests.get() 함수
- HTML 코드 출력
(4) 뷰티플수프
- HTML에서 원하는 태그/텍스트/데이터를 추출하는 기능
① find() 메서드
- 도서 상세 페이지의 URL 찾기
② find_all() 메서드
- 도서 상세 페이지의 HTML 코드 출력
- 특정 HTML 태그를 모두 찾아서 리스트로 출력 (tr 태그)
③ get_text() 메서드
- th 태그 안에 '쪽수, 무게, 크기'에 해당하는 텍스트 찾기
(5) 여러 도서 쪽수 정보 찾기
① apply() 메서드
- 데이터프레임의 각 행 또는 열에 지정한 함수를 반복 적용함
- 각 행에 함수를 적용해야 하므로 axis 매개변수를 1로 지정함 (기본값은 0이며, 각 열에 대해 함수 적용)
1 300쪽
2 228쪽
3 340쪽
4 264쪽
dtype: object
② merge() 함수
- 두 데이터프레임 or 데이터프레임&시리즈 객체를 합칠때 사용
- page_count 시리즈 객체에 name 속성을 활용하여 이름을 지정
- 두 객체의 인덱스를 기준으로 합칠 경우, left_index와 right_index 매개변수를 True로 지정함

2주차. 기본 미션
p150. 확인 문제 1번 풀고 인증하기
문1. 다음과 같은 데이터프레임 df가 있을 때 loc 메서드의 결과가 다른 하나는 무엇인가요?
| col1 | col2 | |
| 0 | a | 1 |
| 1 | b | 2 |
| 2 | c | 3 |
① df.loc[[0,1,2], ['col1', 'col2']]
② df.loc[0:2, 'col1';'col2']
③ df.loc[:2, [True, True ]]
④ df.loc[::2, 'col1':'col2']
→ 정답 ④
| ①~③번은 위 표와 동일하게 출력됨 ④번은 첫번째, 세번째 행만 출력됨 (즉, col1:b / clo2:2는 출력되지 않음) |
2주차. 선택 미션
p137~138. 손코딩 실습으로 원하는 도서의 페이지 수를 출력하고 화면 캡처하기
- '혼자 공부하는 데이터 분석 with 파이썬'의 페이지 수 출력

[혼공분석] #2-1. API로 데이터 수집하기
2. 데이터 수집하기 1) API 사용하기 (1) API란 (2) JSON 다루기 (3) XML 데이터 다루기 (4) API 호출하기 1) API 사용하기 (1) API란 - API: 프로그램 간 데이터를 전달하기 위해 정한 규칙, 데이터베이스 접근
dataslog.tistory.com
'혼공학습단 > 혼자 공부하는 데이터 분석 with 파이썬' 카테고리의 다른 글
| [혼공분석] #4. 데이터 요약하기 (1) | 2024.01.28 |
|---|---|
| [혼공분석] #3-2. 잘못된 데이터 수정하기 (1) | 2024.01.21 |
| [혼공분석] #3-1. 불필요한 데이터 삭제하기 (0) | 2024.01.20 |
| [혼공분석] #2-1. API로 데이터 수집하기 (1) | 2024.01.14 |
| [혼공분석] #1. 데이터 분석을 시작하며 (1) | 2024.01.05 |