1. 데이터 분석을 시작하며
1) 데이터 분석이란
2) 구글 코랩과 주피터 노트북
3) 이 도서가 얼마나 인기가 좋을까요?
1) 데이터 분석이란
(1) '데이터 분석' 및 '데이터 과학'
| 데이터 분석 | 데이터 과학 |
| 유용한 정보를 발견하고 결론을 유추하거나, 의사 결정을 돕기 위해 데이터를 조사, 정제, 변환, 모델링하는 과정 | 통계학, 데이터 분석, 머신러닝, 데이터 마이닝 등을 아우르는 큰 개념 |
| 의사결정을 돕기 위한 통찰을 제공 | 문제해결을 위한 솔루션을 제공 |
(2) 데이터 분석가
- 프로그래밍 기술, 수학/통계, 도메인 지식을 모두 갖춰야 함
- 도메인 지식은 갖추기 어려워 해당 분야의 전문가 도움을 받기도 함
- 작업 과정은 (좁은 의미) 기술통계, 탐색적 데이터 분석, 가설검정, (넓은 의미) 데이터 수집/처리/정제, 모델링을 포함함
(3) 데이터 분석 도구
- R: 통계 패키지 多
- 파이썬: 범용 프로그래밍 언어, 오픈소스
| 파이썬 패키지(라이브러리) | ||||
| 넘파이 | 판다스 | 맷플롯립 | 사이파이 | 사이킷런 |
| 다차원 배열 | 엑셀 시트 | 시각화 | 통계 분석 | 머신러닝 |
2) 구글 코랩과 주피터 노트북
| 구글 코랩 | 주피터 노트북 |
| 설치 불필요 (클라우드 기반) | 설치 필요 |
| 온라인 웹 브라우저 | 오프라인 웹 브라우저 |
| 구글 드라이브에 저장 | 하드 디스크에 저장 |
(1) 구글 코랩
- 웹 브라우저에서 무료로 파이썬 프로그램을 이용할 수 있는 온라인 에디터
- 코랩의 프로그램 파일을 노트북이라고 함
- http://colab.research.google.com
Google Colaboratory
colab.research.google.com
① 셀
| 텍스트 셀 | 코드 셀 |
| 자유롭게 사용 가능 (HTML, 마크다운 혼용) | 파이썬 코드 입력 및 실행 |
| 편집: Enter or 해당 셀 클릭 수정 완료: ESC or 다른 셀 클릭 |
실행: Ctrl + Enter 실행 후 다음 셀 이동: Shift + Enter 실행 후 다음 셀 추가: Alt + Enter |
② 노트북
- 생성: 파일 - 새 노트
- 저장(구글 드라이브): 파일 - 저장, Ctrl + S
- 저장(하드 디스크): 파일 - 다운로드
- 열기: 파일 - 노트 열기
(참고) 이 책의 모든 코드는 깃허브에 저장됨 https://github.com/rickiepark/hg-da
3) 이 도서가 얼마나 인기가 좋을까요?
(1) 도서 판매량 데이터 찾기
- 공공데이터포털
- 네이버검색(도서관 대출 데이터) → 도서관 정보나루
- 데이터 과학 관련 온라인 포럼
(2) 데이터 확인하기 - open() 함수
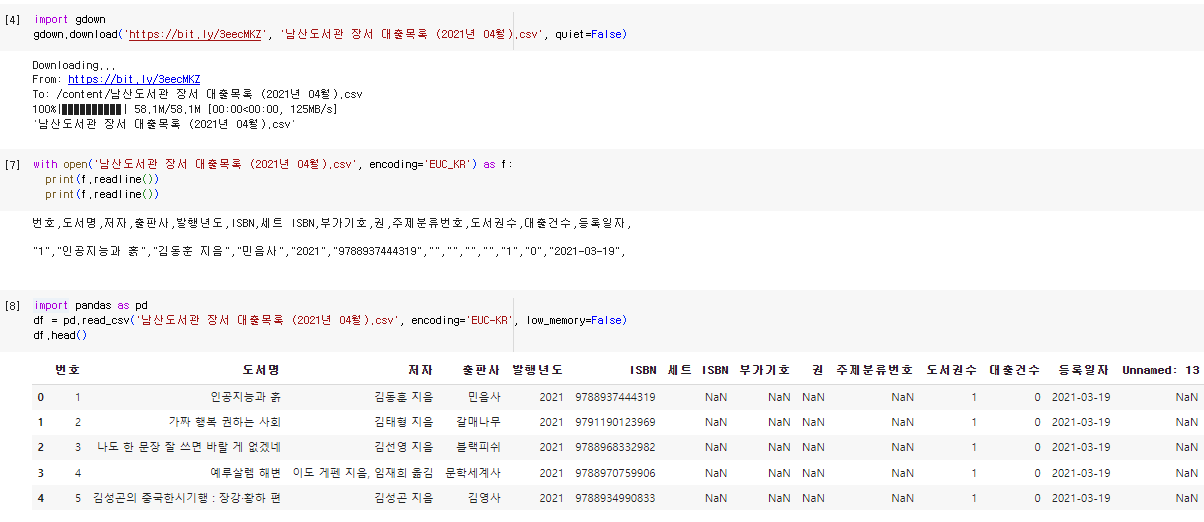
① 코랩에 데이터 다운: gdown 패키지
- gdown 패키지: 웹에서 대용량 파일을 다운로드 할 수 있는 패키지
② csv 파일 출력하기: open() 함수
- with문으로 파일을 열고, open() 함수로 읽고, readline() 메서드로 한 줄 출력
- 인코딩 형식을 'EUC-KR' 한글로 지정
번호,도서명,저자,출판사,발행년도,ISBN,세트 ISBN,부가기호,권,주제분류번호,도서권수,대출건수,등록일자,
"1","인공지능과 흙","김동훈 지음","민음사","2021","9788937444319","","","","","1","0","2021-03-19",
(3) 데이터 확인하기 - 판다스
- 판다스는 csv 파일을 읽어 데이터프레임(행X열) 형태로 저장함
① csv 파일 읽기: read_csv() 함수
- as 키워드로 패키기 이름을 pd로 줄임
- read_csv() 함수: 판다스에서 csv 파일을 읽을 때 사용함
- 동일 열 내 데이터 타입이 다를 경우, 오류가 발생함
→ low_memory=False로 지정하여 파일을 한 번에 읽음
- head() 메서드: 처음 다섯 개 행을 출력함
② csv 파일로 저장: to_csv() 메서드
- to_csv() 메서드: csv 파일로 저장할 때 사용함
- UTF-8 형식으로 저장되어, 파일 읽을 때 인코딩 형식을 지정하지 않아도 됨
- 'ns_201404' 파일명으로 저장하고, 3줄 출력함
1,2,가짜 행복 권하는 사회,김태형 지음,갈매나무,2021,9791190123969,,,,,1,0,2021-03-19,

1주차. 기본 미션
p81. 확인 문제 4번 풀고 인증하기
문4. 판다스 read_csv() 함수의 매개변수 설명이 옳은 것은 무엇인가요?
① header 매개변수의 기본값을 1로 CSV 파일의 첫 번째 행을 열 이름으로 사용합니다. → 기본값은 'infer'
② names 매개변수에 행 이름을 리스트로 지정할 수 있습니다. → 열
③ encoding 매개변수에 CSV 파일의 인코딩 방식을 지정할 수 있습니다.
④ dtype 매개변수를 사용하려면 모든 열의 데이터 타입을 지정해야 합니다. → 필요한 열
→ 정답 ③
| - header 매개변수: 열 이름으로 사용할 행 번호 지정 * 첫 행이 열 이름이 아닌 경우, header 매개변수를 None으로 지정하고 names 매개변수에 열 이름 리스트를 전달 - names 매개변수: 열 이름의 리스트를 지정 (열 이름 중복X) - encoding 매개변수: 해당 파일의 인코딩 방식 지정 - dtype 매개변수: 필요한 열의 데이터 타입 지정 |
1주차. 선택 미션
p71~73. 남산 도서관 데이터를 코랩에서 데이터프레임으로 출력하고 화면 캡처하기
'혼공학습단 > 혼자 공부하는 데이터 분석 with 파이썬' 카테고리의 다른 글
| [혼공분석] #4. 데이터 요약하기 (1) | 2024.01.28 |
|---|---|
| [혼공분석] #3-2. 잘못된 데이터 수정하기 (1) | 2024.01.21 |
| [혼공분석] #3-1. 불필요한 데이터 삭제하기 (0) | 2024.01.20 |
| [혼공분석] #2-2. 웹 스크래핑으로 데이터 수집하기 (0) | 2024.01.14 |
| [혼공분석] #2-1. API로 데이터 수집하기 (1) | 2024.01.14 |